Research
Here is a brief summary of my research projects, current and past. I have designed it in a way that is accessible to both linguists and non-linguists.
For more information, please don’t hesitate to get in touch!
The CAT’s Out the Bag: A study of real-time sound change in the socially stratified Glaswegian CAT vowel
Alongside my PhD, I am very interested in looking at sound change and different analytical methods we can use to get a better picture of what is going on. I looked at the CAT vowel quality in Glasgow over the last 60 years, and whether it is socially stratified in its quality between the working-class and middle-class communities.
The Glaswegian CAT vowel (equivalent to British English TRAP/BATH/PALM) has been shown to be relatively stable over time with a little bit of wobbling around, but not significantly so. However, recent research has found this vowel quality to be significant in marking community membership in Glaswegian high school, and political party affiliation.
My questions were to see if 1) the CAT vowel is socially stratified between working-class (WC) and middle-class (MC) Glaswegians, and 2) if this stratification changed over time. For example, sometimes the two communities may be quite similar, but in the next decade they may be extremely distinct.
I employed an alternate statistical method to look at sound change over time, with the use of Generalised Additive Mixed Models (GAMMs). This type of modelling allowed me to look at any non-linear relationships between the vowel quality over time, and plot two separate trajectories for the speech community – allowing me to identify any key points in time for sound change. In the below example of what GAMM modelling can facilitate, you can see two trajectories of the working-class CAT vowel (orange) and middle-class CAT vowel (grey) and their F2 values over time.
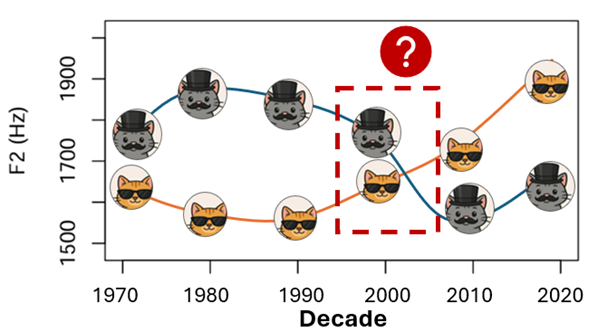
To look at this, I created a large-corpora of forced-aligned speech data from multiple sources. Speech was obtained from 79 speakers across six decades, male and female, and aged 25-65 years of age (from Glasgow/greater Glasgow area). Vowel normalisation took place, and log-transformation of vowel duration. I then filtered the dataset to have just CAT vowels (that did not precede liquids /r,l/). This resulted in 9,777 individual tokens.
I created GAMMs to look at both vowel height (F1) and frontness/backness (F2). With this, I could model any overall changes that may fluctuate over time between the speech of the two social classes of Glasgow.
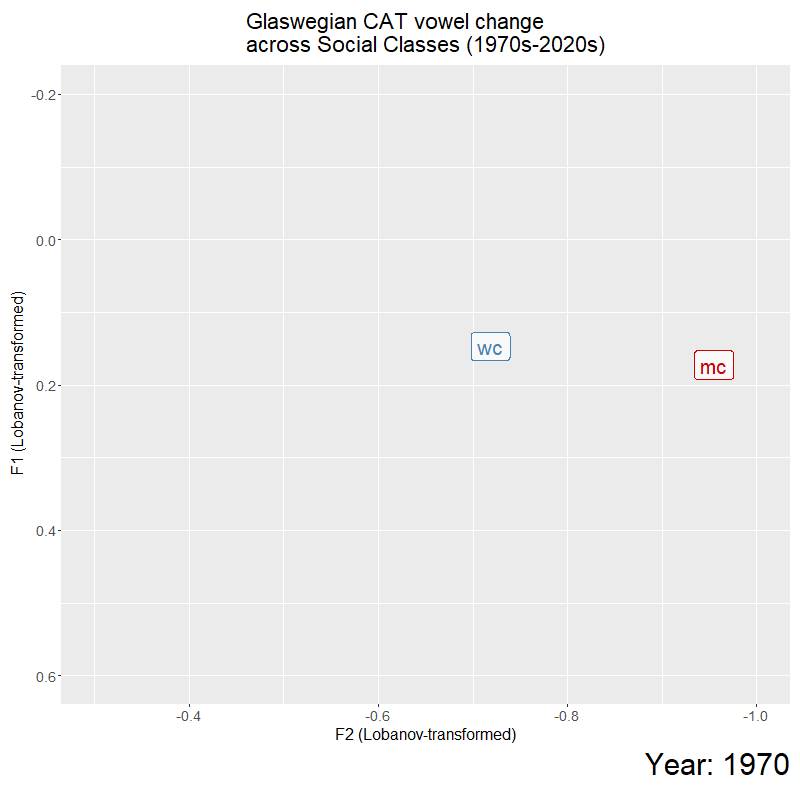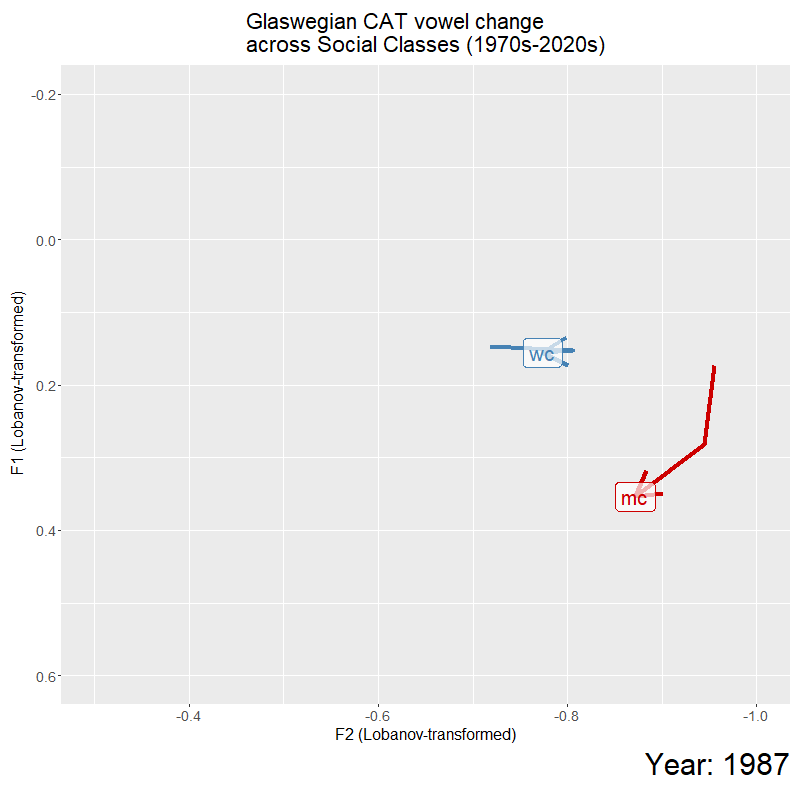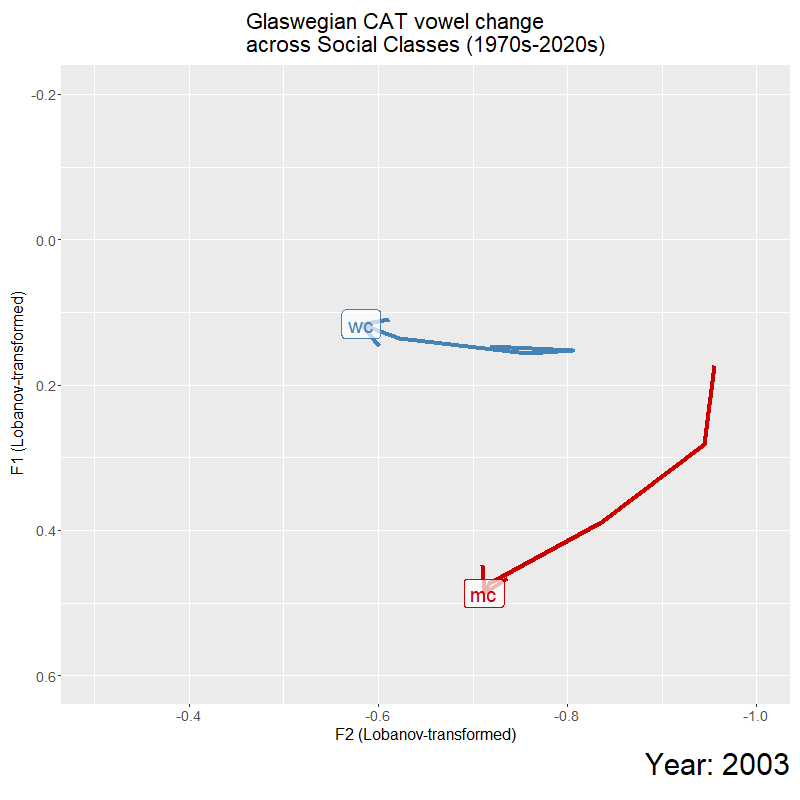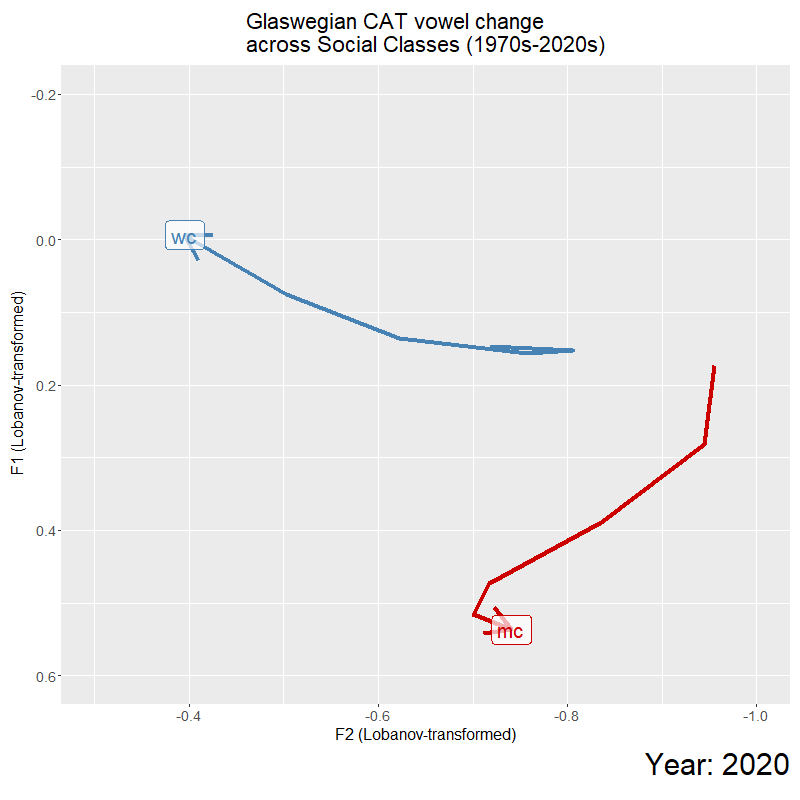
For my presentation at UKLVC15, I plotted these trajectories as an animation to help visualise the trends in the data. I explored the significant stratification between the two classes, and trajectory divergence which saw the 2000s as a ‘temporal catalyst’ of change, and significant effect of time for the divergence between the classes. For this conference, I explored the social relevance of this timepoint (in a sociolinguistic variationist perspective), to see how changing social meaning, that was indexed by this vowel quality, could be contributing towards this sound change. This involved looking at emerging sub-cultures in Glasgow at this time, the role of the media in transmitting ideologies, and active negotiation of working-class and middle-class identity with the use of super-local variation such as CAT vowel quality (a very condensed down version).
For anymore information regarding this project, please do not hesitate to get in touch.
Let’s talk about Class - UK perceptions of social class and personality traits
How do we measure bias and perceptions of people? To first do this, we need to use materials/stimuli that are normed for various levels of social class and personality traits. I will be using these normed materials in my eye-tracking experiment: a novel implicit method in examining unconscious accent biases.

To achieve this, I conducted a large-scale perceptual study (over 200 participants). I explored their perceptions towards social class and judgements of personality traits according to exhibited social behaviours. This is to create a novel, database of 110 stimuli objects that are normed for the representative levels of social class (working-class vs middle-class) and social traits (low vs high level of a trait).
This normed database of materials will be used in my own PhD research, but will be available online very soon. Additionally to this, I explored variation in population biases according to individual’s background (i.e., age, geographic origins, social class and sexual identity). This illustrated fascinating insights into bias formation and variation across society. Get in touch if you would like to know more!
Accentuating Identities
For part of my PhD research, I am interested in how accents are used in the media. Accents can be used to build character identities, by allowing us to rely on social stereotypes present in society. Using accents and language varieties can be a useful technique to cultivate these fictional worlds, but it can lead to accent bias and accent-based stereotyping in society.
To look at how accents are portrayed in the media, I have conducted an empirical investigation into how the Glaswegian vernacular (GV) accent is portrayed in film.

This research is the first quantitative examination of UK accent portrayals in film, with a focus on the GV accent. We analysed 5825 data points from 233 characters across 12 films, evaluating characters on 25 social and behavioural traits.
Significant patterns were found in the data, where GV accented characters were portrayed with considerably heightened levels of stigmatised behaviours (e.g., profanity use, substance use, aggression) and downgraded levels of competence (e.g., intelligence). This corresponds to what is already present in language attitude research on the perception of Glaswegians.
Data modelling was carried out to visualise these patterns even further. Like we can see below, with the predicted probability of an imaginary character, based on their accent. We see that GV has one of the largest proportions of ‘5’, showing extreme levels of profanity use.
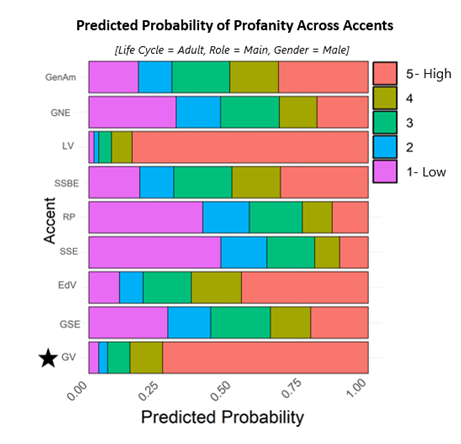
From this small dataset, significant patterns of accent bias are present. We know that accents are a salient tool in creating fictional worlds, and we might even argue that accent-based stereotypes are part and parcel of the nature of depicting society. But, does this reliance on the social information imbued in accents further reinforce our biases and stereotypes?
For anyone interested, analysis for this study used non-parametric testing and cumulative link mixed models. These are handy tools when dealing with ordinal data such as Likert data.
A Game of Phones

For my Masters dissertation, I conducted a socio-phonetic analysis of Yorkshire English in Game of Thrones and presented my findings at the International Congress of Phonetic Sciences 2023.
Accents in media, like Game of Thrones, provide quick cues for audiences to understand characters and social hierarchies, often mapping real-world stereotypes onto fictional worlds. For example, the prestigious Lannister family speak in Received Pronunciation (RP), which we associate with royalty.

To look at mediated accent portrayals of the Yorkshire accent, I analysed three characters’ Yorkshire performances in Game of Thrones: native Yorkshire speaker Sean Bean and non-native speakers Kit Harrington and Richard Madden. Using acoustic analysis, I examined the following Yorkshire accent features: STRUT-FOOT vowel merger and monophthongal variants of GOAT & FACE vowels.
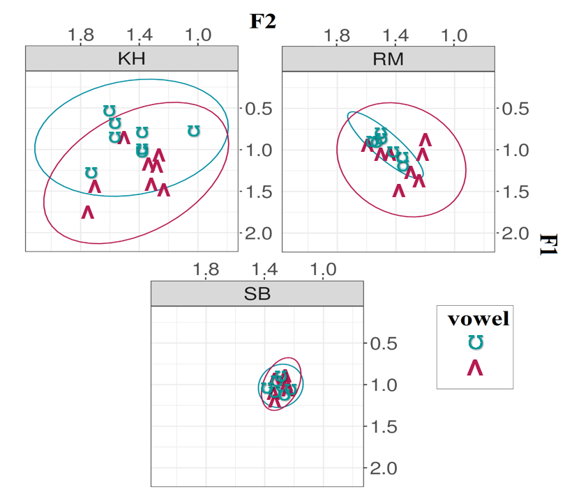
(Jackson, 2023)
| In most Yorkshire accents, the STRUT and FOOT vowels [ʌ-ʊ] are merged. As a Yorkshire lass myself, I would say both these words with the exact same vowel as they are merged for me. Similarly, you can see these vowels merged by the Sheffield actor, Sean Bean (SB). However, the non-native actors (KH and RM) fail to produce a STRUT-FOOT merger in their Yorkshire performances. |
| Moving on to the monophthongal FACE and GOAT variants [eɪ, əʊ] in the Yorkshire accent, rather that the common diphthongal quality we hear in most other UK English accents. We can see that Sean Bean (SB) demonstrates minimal movements across the vowel trajectory (25%, 50% and 75% point of the vowel), making his FACE and GOAT vowels very monophthongal (as expected). Unfortunately, the non-native actors seem to really struggle with this, and can’t seem to shake the extra movement we would see in their own native accents. |
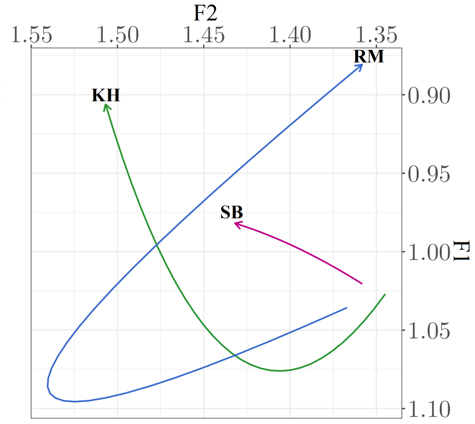 FACE vowel - (Jackson, 2023) FACE vowel - (Jackson, 2023) |
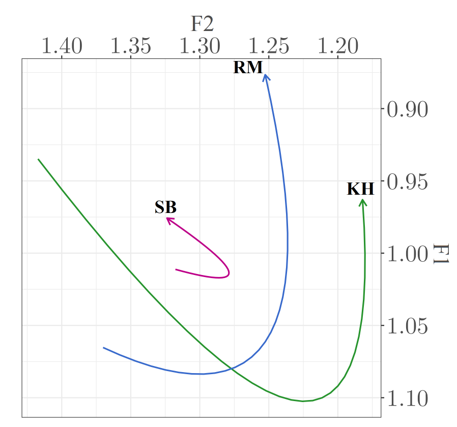 GOAT vowel - (Jackson, 2023) GOAT vowel - (Jackson, 2023) |
| We can see from above that the non-native speakers are struggling to consistently replicate Yorkshire features similar to what is expected in native Yorkshire speech. The second part of this study asked lay listeners (not phonetically trained) to ‘blindly’ rate these performances. Listeners rated Sean as the most credible Yorkshire speaker, while Kit and Richard were rated less favourably, with listeners using these performances to predict their true origins. |
An interesting add-on was that listeners were then asked to predict what these Yorkshire voices would look like. Descriptions such as savage, dirty, a bit dim but loyal were all given. Which, interestingly, corresponds to the overall appearance of the Starks family, as the dishevelled, Northern underdogs.
In short, non-native speakers failed to consistently produce Yorkshire phonetic features, and listeners picked up on these discrepancies, linking them to the speakers’ actual origins. Listeners were also found to use the phonetic signal (the accent) to make predictions about the speakers’ social behaviours and appearances. This raises questions about the reinforcement of stereotypes through media portrayals of accents.
And perhaps, we are all just playing the game of phones to decipher social meaning through language.
